Le numérique est un des enjeux de la revitalisation des langues minoritaires. Dans ce domaine, l’écart entre langues « bien dotées » (moins d’une dizaine de langues)1 et langues « peu dotées » se creuse considérablement (Rehm et al., 2014 ; Soria et Mariani, 2013). Cet écart est documenté également en France, où l’on constate que les langues régionales sont très peu dotées en ressources et outils numériques, en comparaison au français (Leixa, Mapelli et Choukri, 2014). Il est indispensable pour toutes les langues, et a fortiori pour les langues dites « minoritaires », de se faire une place dans l’ère du numérique pour renforcer leur visibilité, faciliter leur utilisation, accompagner leur enseignement. Des recommandations ont d’ailleurs été récemment émises à ce sujet, dans le cadre du Digital Language Diversity Project (Ceberio Berger et al., 2018). Or, les langues disposant de peu de ressources ont en commun que leur informatisation a une faible rentabilité qui ne compense pas des coûts de développement importants. Le défi que constitue la constitution de ressources et d’outils électroniques pour ces langues est donc considérable.
Le projet RESTAURE2 (RESsources informatisées et Traitement AUtomatique pour les langues REgionales), financé par l’ANR (2015-2018)3 a eu pour objectif de fournir des ressources numériques (en particulier à travers la constitution de corpus et lexiques) et d’outils de traitement automatique des langues (TAL) pour trois langues dites « régionales » de France : l’alsacien, l’occitan et le picard.
Nous allons dans un premier temps présenter ce projet, à travers ses objectifs et les langues traitées. Puis seront détaillés certains défis méthodologiques qui ont été soulevés : données et outils numériques rares et éparses, descriptions des langues incomplètes, variations dialectales et graphiques. Ces défis ne sont pas spécifiques aux langues du projet et sont représentatifs des difficultés lors de travaux portant sur les langues dites « peu dotées ». Nous discuterons ensuite des solutions qui ont été proposées, sur la base de recommandations visant à améliorer la vitalité numérique4 des langues minoritaires et peu dotées (Soria, Mariani et Zoli, 2013 ; Ceberio Berger et al., 2018) : coopération, utilisation de standards, réutilisabilité des ressources et outils. Enfin, nous conclurons en détaillant les leçons tirées du projet RESTAURE.
1. Présentation du projet RESTAURE
1.1. Participants et objectifs
Le projet RESTAURE a réuni des chercheurs de quatre unités de recherche situées à Strasbourg (Université de Strasbourg — LiLPa UR 1339), Toulouse (Université Toulouse Jean-Jaurès — CLLE-ERSS), Amiens (Université de Picardie Jules Verne — Habiter le monde) et Orsay (LIMSI), spécialistes à la fois des trois langues du projet (alsacien, occitan et picard) et du traitement automatique des langues. Il avait trois objectifs principaux :
- développer des ressources (corpus et lexiques) ;
- développer des outils pour l’acquisition et l’analyse de corpus écrits ;
- diffuser ces ressources et outils auprès des chercheurs et des non spécialistes.
Ces objectifs répondaient à des besoins en ressources et outils numériques identifiés lors du dépôt du projet et prenant en compte l’existant. La situation des différentes langues avant le démarrage du projet est résumée dans le tableau 1. Ce tableau rend compte de nombreux déficits et d’une situation hétérogène en terme d’expériences et de besoins. Elle reflète également l’état des lieux établi en 2014 dans l’Inventaire des ressources linguistiques des langues de France (Leixa, Mapelli et Choukri, 2014) qui indique un volume faible de ressources linguistiques pour l’alsacien (8/10)5 et les langues d’oïl (7/10), dont le picard6 fait partie, et moyen pour l’occitan7 (5/10), qui se situe au même niveau que le breton et en deçà du basque (4/10) ou du catalan (4/10). Le français obtient le meilleur classement parmi les langues de France avec un score de 3/10.
Tableau 1 : Ressources et outils avant le début du projet
| Ressource/ outil | alsacien | occitan | picard |
| Corpus brut | ∅ | BaTelÒc base expérimentale (Bras et Thomas, 2008) | PICARTEXT |
| Corpus annoté | ∅ | ∅ | ∅ |
| Lexique et dictionnaires | (Bernhard, 2014) | Dico d’òc (Congrès Permanent de la Lenga Occitana) en cours de construction | ∅ |
| Tokéniseur | ∅ | ∅ | ∅ |
| Étiqueteur morphosyntaxique | (Bernhard et Ligozat, 2013a ; Bernhard et Ligozat, 2013b) | (Vergez-Couret, 2013 ; Vergez-Couret et Urieli, 2014) | ∅ |
| Analyseur syntaxique | ∅ | ∅ | ∅ |
| Niveau de classement établi par (Leixa, Mapelli et Choukri, 2014) | 8 | 5 | 7 |
Il est à noter que les notions de corpus, lexique ou dictionnaire utilisées dans le cadre du projet RESTAURE désignent des ressources directement utilisables pour des travaux en traitement automatique des langues8. Ainsi, des textes ou des lexiques qui seraient disponibles dans des formats numériques non structurés ou semi-structurés (pages web, PDF, document traitement de texte) ne constituent pas à proprement parler des ressources directement exploitables sans travaux préparatoires : extraction et balisage des éléments d’intérêt, suppression des informations inutiles, transformation vers un format standard comme TEI (TEI Consortium, 2020).
De plus, certaines ressources existantes, comme le Dico d’òc contiennent des données structurées directement exploitables pour des travaux en traitement automatique des langues mais ne sont pas nécessairement disponibles en totalité pour la recherche en raison du droit de propriété intellectuelle.
1.2. Langues du projet
Le tableau 2 ci-dessous dresse un bref état comparatif des trois langues du projet, selon diverses caractéristiques : famille linguistique, situation sociolinguistique, production écrite et standardisation à l’écrit. Il montre les différences entre les langues du projet, mais aussi leurs points communs.
Tableau 2 : Comparatif des trois langues du projet RESTAURE
| Caractéristiques | alsacien | occitan | picard |
| Famille linguistique | langue germanique / haut-allemand |
langue romane / gallo-roman méridional |
langue romane / gallo-roman septentrional |
| Situation sociolinguistique | Dialectes utilisés principalement dans des contextes informels. Pas d’enseignement à l’école publique, mais dans quelques écoles associatives. |
Utilisation de la langue dans toutes ses variantes dialectales dans des contextes formels (enseignement, recherche, presse, médias) et informels. Enseignement public et associatif (initiation bilingue, immersion) |
Dialectes utilisés principalement dans des contextes informels. Pas d’enseignement à l’école publique. |
| Production écrite | Utilisé à l’écrit depuis au moins la seconde moitié du XVIIe siècle, dans deux genres principaux : pièces de théâtre et poésie. D’autres genres sont aussi représentés : prose poétique, chansons, comptines, contes, traductions et adaptation d’œuvres dans d’autres langues. Les textes en prose sont assez rares. |
Production écrite littéraire abondante et continue depuis les troubadours au Moyen-Âge. Tous les genres sont représentés : poésie, prose, théâtre, chansons, contes, comptines, presse, textes techniques, incluant traductions. |
Utilisé à l’écrit dans tous les genres littéraires dont les plus représentés : théâtre, fable, roman, récits brefs, poésie, chanson. |
| Standardisation typo-orthographique |
Propositions récentes de conventions orthographiques (par exemple ORTHAL (Zeidler et Crévenat-Werner, 2008)), mais leur utilisation n’est pas généralisée. |
Co-existance de deux standards principaux : graphie mistralienne et graphie classique. Nombreuses graphies individuelles. |
Pas de standardisation. |
| Nombreuses graphies individuelles |
2. Défis et solutions mises en œuvre
Les défis rencontrés lors du projet ont directement trait aux langues traitées. Il s’agit, comme nous l’avons montré précédemment, de langues peu dotées, ce qui entraîne des difficultés liées à l’acquisition et à l’annotation de données. Par ailleurs, ces langues ne sont pas uniformes et normées comme peut l’être le français standard à l’écrit, ce qui induit des variations dialectales et orthographiques.
Les solutions mises en œuvre répondent quant à elles à trois principes essentiels : la collaboration entre chercheurs, la réutilisation et le recyclage d’outils existants et l’utilisation de standards. Ces principes suivent les recommandations données par Soria et al. (2013) dans un article en faveur du développement des technologies des langues pour les langues dites régionales et/ou minoritaires. Dans ce même article, Soria et al. préconisent de documenter les ressources et outils et de les partager, avec des licences permettant leur réutilisation par d’autres chercheurs. Ces diverses recommandations vont dans le sens des principes FAIR (Findable Accessible Interoperable Reusable) pour repérer les ressources numériques, les rendre accessibles et interopérables et faciliter leur réutilisation (Wilkinson et al., 2016).
2.1. Acquisition et annotation de données
Le premier défi d’importance concerne les données et le « goulot d’étranglement » que constitue le passage des données brutes aux données enrichies par des annotations linguistiques ; ce dernier problème se rencontre d’ailleurs également pour les langues mieux dotées, mais dans une moindre mesure.
La figure 1 ci-dessous représente ce goulot d’étranglement et les différents défis auxquels il faut faire face.
Figure 1 : Passage des données brutes aux données annotées
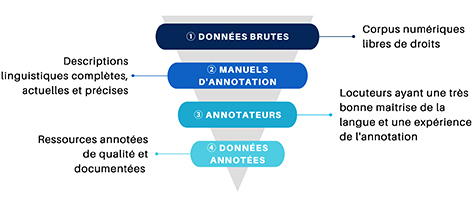
1. La collecte des données brutes (corpus de textes) est rendue difficile par la faible quantité de ressources disponibles. À cela s’ajoute la difficulté à trouver des données dont les droits d’utilisation permettent une diffusion libre des corpus collectés pour des besoins de recherche, en particulier pour les textes les plus récents (Kevers et Retali-Medori, 2019). En conséquence, les données collectées sont de taille relativement faible, en comparaison aux corpus généralement exploités en TAL9.
2. Des descriptions linguistiques précises et complètes sont nécessaires pour enrichir les corpus d’annotations (partie du discours, propriétés morphosyntaxiques) et produire des guides d’annotation. Il n’est pas toujours facile de trouver des grammaires de bonne qualité pour les langues régionales de France et, si elles existent, elles peuvent être dépassées ou incomplètes.
3. Le recrutement de personnes qui sont à la fois des locuteurs ayant une bonne maîtrise de la langue et des annotateurs expérimentés n’est pas une chose aisée.
4. Enfin, comme pour toute tâche d’annotation de corpus, il est nécessaire d’appliquer des procédures d’assurance qualité et de rédiger une documentation, en vue de la diffusion des ressources annotées. La vérification de la qualité des données annotées passe par une phase d’adjudication. Cette phase est également chronophage.
Les participants au projet avaient différents domaines de spécialité (sociolinguistique, linguistique descriptive, dialectologie, traitement automatique des langues, humanités numériques) et différents niveaux d’expérience dans la production de ressources et la manipulation d’outils de TAL. Or, le développement d’outils de TAL est coûteux et nécessite des compétences spécifiques. Les technologies évoluent de surcroît très rapidement et demandent donc des améliorations ou mises à jour constantes sous peine de voir les outils devenir rapidement obsolètes. Le processus d’annotation représenté par la figure 2 a été l’occasion pour les chercheurs de coopérer et s’entraider en fonction de leurs compétences. Un autre point important a été le recyclage d’outils et de ressources existantes, ainsi que l’encouragent Soria et al., 2013.
Figure 2 : Processus d’annotation de corpus
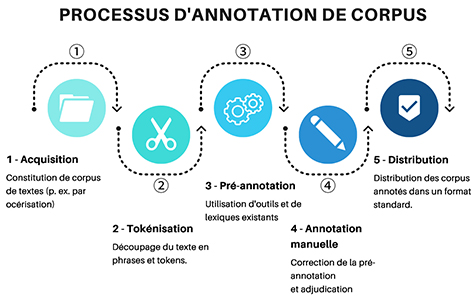
Par exemple, le travail sur l’étape 1 d’acquisition de corpus par reconnaissance optique de caractères (OCR) a donné lieu à un travail commun entre Strasbourg et Toulouse, afin d’évaluer et d’entraîner deux outils différents, Tesseract (Smith, 2007) et Jochre (Urieli et Vergez-Couret, 2013), pour l’alsacien et l’occitan (Vergez-Couret et al., 2017). Le développement d’un tokéniseur pour le picard a été réalisé conjointement par des chercheurs de Strasbourg et d’Amiens (Bernhard et al., 2017). Le travail d’annotation de corpus et de constitution de lexiques pour le picard effectué à Amiens a été largement soutenu par les chercheurs du LIMSI à Orsay. L’annotation des corpus alsaciens et occitans s’est faite à l’aide d’un outil appelé AnaLog (Lay et Pincemin, 2010), avec une pré-annotation réalisée à l’aide d’outils étiquetage morphosyntaxique existants : Talismane (Urieli et Vergez-Couret, 2013), TreeTagger (Schmid, 1994), Apertium (Armentano I Oller, 2008).
La collaboration entre chercheurs nécessite toutefois des efforts de coordination et se heurte aussi à des problèmes liés au cadre même d’un projet coopératif : enchaînement des recrutements, temps disponible pour les enseignants-chercheurs, problème de la distance, dialogue entre disciplines très différentes. En ce sens, la figure 2 donne une représentation idéale du processus d’annotation qu’il peut être nécessaire d’ajuster en fonction des langues et de ce qu’il est possible de faire pour les chercheurs impliqués.
Cela étant, nous pouvons affirmer rétrospectivement que de nombreuses tâches n’auraient pu être accomplies, ou alors sous une forme moins sophistiquée, sans la collaboration entre les différentes équipes. Cette coopération a permis de compenser, dans une certaine mesure, le manque de ressources humaines et de spécialistes du traitement automatique pour les langues régionales étudiées. Le travail parallèle sur plusieurs langues a permis de gagner en efficacité en bénéficiant des expériences réalisées sur d’autres langues. Les problèmes qui se sont posés dans une langue ont conduit à une vigilance accrue sur ces sujets dans les autres langues.
2.2 Variations dialectales et orthographiques
L’alsacien, l’occitan et le picard ne sont pas des langues homogènes ni totalement standardisées à l’écrit. Différentes variétés ou dialectes peuvent être identifiés dans chaque région. Les conventions orthographiques pour l’écrit sont soit assez récentes, soit peu utilisées, soit conçues de manière à rendre compte des particularités dialectales. Ces variations ont un impact négatif sur le développement d’outils de TAL. D’une part, l’absence ou le non-respect de normes orthotypographiques impacte la première étape de la chaîne de traitement (tokénisation), qui consiste à identifier les unités de base que sont les mots, signes de ponctuation, symboles ou autres. L’utilisation irrégulière ou inattendue des signes de ponctuation ou des espaces complique cette phase (Bernhard et al., 2017). Par exemple, en picard, l’apostrophe peut marquer l’élision d’une voyelle au milieu d’un mot (ramintuv’lant/souvenant) ou à la frontière (m’/me l’/le). Dans le premier cas, il n’est pas séparateur, alors qu’il l’est dans le deuxième cas :
In m’ ramintuv’lant l’ timps passé,…
En me souvenant le temps passé,…
Par ailleurs, les outils de TAL sont très sensibles au problème des mots inconnus ou « hors vocabulaire » (OOV - Out Of Vocabulary). Les mots hors vocabulaire sont des mots qui ne sont pas connus d’un système car il est tout simplement impossible de lister tous les mots possibles d’une langue (formes rares, néologismes, entités nommées, formes erronées, etc.). Les mots hors vocabulaire sont problématiques pour le traitement automatique de toutes les langues, et encore plus dans les langues peu dotées et présentant des variantes orthographiques (voir par exemple [Snoeren, Adda-Decker et Adda, 2010] pour le luxembourgeois). Les stratégies visant à réduire le nombre de mots inconnus cherchent généralement à normaliser les variantes orthographiques vers une forme connue : forme contemporaine dans le cas des états anciens d’une langue (Bollmann, 2019), forme standard pour la communication médiée par ordinateur (Mosquera, Lloret et Moreda, 2012) ou pour des variantes dialectales (Frey, Glaznieks et Stemle, 2015). Il est également possible de simplement détecter les variantes, sans pour autant chercher à les normaliser (Dasigi et Diab, 2011 ; Barteld, Biemann et Zinsmeister, 2019), ce qui évite d’avoir à choisir une norme ou de trouver des solutions pour les formes qui ne trouvent pas facilement une correspondance dans cette norme (formes disparues ou spécifiques à la variante étudiée). Une solution intermédiaire, lors de l’annotation manuelle d’un corpus, consiste à indiquer une glose dans une autre langue (Jarrar et al., 2016), ce qui permet d’identifier facilement les variantes ayant la même traduction, tout en offrant une désambiguïsation sémantique. Nous avons privilégié cette dernière solution (voir section 3.2 pour des exemples).
3. Impacts du projet
Il existe diverses manières de mesurer l’impact du projet, en fonction de différents points de vue. Il est ainsi possible de faire un bilan scientifique « objectif » des ressources produites, en incluant leur mode de diffusion et leur potentiel de réutilisation dans le cadre de nouveaux travaux de recherche. Un autre bilan, plus difficile à réaliser, concerne les éventuelles contributions au développement des langues dites minoritaires concernées, que ce soit dans le milieu de la recherche universitaire ou auprès des locuteurs de ces langues.
3.1. Bilan scientifique
Le tableau 3 ci-dessous dresse un récapitulatif des travaux réalisés par les équipes du projet RESTAURE, en incluant également les travaux cités dans le tableau 1.
Tableau 3 : Récapitulatif des ressources et outils produits dans le cadre du projet RESTAURE
| Ressource / outil | alsacien | occitan | picard |
| Corpus brut | (Bernard et al, 2018a) | BaTelÒc base opérationnelle (Bras et Vergez-Couret, 2016) | PICARTEXT |
| Corpus annoté | (Bernard et al, 2018a) | (Bras et al., 2018) | (Martin, Rey et Reynés, 2018) |
| Lexiques et dictionnaires | (Bernhard, 2014 ; Bernhard et al., 2018b ; Steiblé et Bernhard, 2018) | LoFlòc (Vergez-Couret, 2016 ; Bras et al., 2017) | ∅ |
| Tokéniseur | (Bernard, 2018) | (Vergez-Couret, 2019) | (Todirascu, 2018 ; Ligozat, 2018) |
| Étiqueteur morphosyntaxique |
(Bernhard et Ligozat, 2013a ; Bernhard et Ligozat, 2013b) | (Vergez-Couret, 2013 ; Vergez-Couret et Urieli, 2014 ; Vergez-Couret et Urieli, 2015) | ∅ |
| (Magistry et al., 2018 ; Magistry et al., 2019) | |||
| Analyseur syntaxique | ∅ | ∅ | ∅ |
En particulier, nous avons choisi de partager les corpus annotés produits par le projet RESTAURE dans le format CONLL-U10, défini dans le projet Universal Dependencies (Nivre et al., 2016). Ce projet définit par ailleurs 17 parties du discours considérées comme universelles11. L’utilisation de standards de la communauté scientifique est importante, car elle permet de faciliter la réutilisation des ressources grâce à l’utilisation d’un modèle commun.
Nous avons utilisé ces catégories dans la diffusion de nos corpus annotés, après avoir projeté les étiquettes utilisées pour l’annotation initiale (VO) vers les parties du discours Universal Dependencies (UD) (Miletic et al., 2019). Ces corpus donnent également la traduction en français pour chaque mot ainsi que le lemme, en plus de la forme trouvée dans le texte. Comme nous l’avons expliqué dans la section 2.2, l’ajout de la glose en français est utile car elle permet d’identifier les variantes à partir de leur traduction. Elle rend aussi possible la constitution de lexiques bilingues à partir des corpus annotés.
Les tableaux 4 à 6 ci-dessous donnent des exemples pour l’alsacien, l’occitan et le picard.
Tableau 4 : Exemple d’annotation pour l’alsacien
| tokens | VO | UD | lemme | glose |
| Mìtem | APPRART | ADP | mìt | avec |
| DET | de | le | ||
| Sabayon | NOUN | NOUN | Sabayon | sabayon |
| ìwwerzìehje | VERB | VERB | ìwwerzìehje | napper |
| ùn | CONJ | CCONJ | ùn | et |
| mìt | ADP | ADP | mìt | avec |
| de | DET | DET | de | les |
| g’hobelte | ADJ | ADJ | g’hobelt | effilé |
| Màndle | NOUN | NOUN | Màndel | amande |
| bstraie | VERB | VERB | bstraie | saupoudrer |
| . | PUNCT | PUNCT | . | . |
Tableau 5 : Exemple d’annotation pour l’occitan
| tokens | VO | UD | lemme | glose |
| Cossí | Rx | ADV | cossí | comment |
| aquò | Pd | PRON | aquò | ça |
| pòt | Vm | VERB | poder | pouvoir |
| èsser | Vm | VERB | èsser | être |
| ? | F | PUNCT | ? | ? |
Tableau 6 : Exemple d’annotation pour le picard
| tokens | VO | UD | lemme | glose |
| Il | PRONPERS | PRON | Il | Il |
| est | VERBCONJ | VERB | ète | est |
| rétampi | ADV | ADV | rétampir | debout |
| d’puis | ADP | ADP | depuis | depuis |
| bientout | ADV | ADV | bientôt | bientôt |
| troés | NUM | NUM | troés | trois |
| ins | NOUN | NOUN | in | ans |
| . | PUNCT | PUNCT | . | . |
L’utilisation de ces standards permettra à l’avenir d’entraîner facilement d’autres outils pour la tokénisation et l’étiquetage morphosyntaxique comme UDPipe (Straka et Straková, 2017) ou Stanza (Qi et al., 2020). En effet, la plupart des outils de TAL actuels sont capables d’apprendre à partir des données. Les méthodes ont évolué, passant d’approches essentiellement fondées sur des règles à des techniques d’apprentissage automatique, qui sont en principe applicables à une grande variété de langues. La condition principale est que des données soient disponibles pour les réutiliser. Nous avons donc choisi de nous concentrer sur la collecte et l’annotation des données, plutôt que sur le développement d’outils. Comme souligné précédemment, les outils peuvent ensuite être réutilisés ou recyclés.
Pour la diffusion des ressources produites, nous avons veillé à respecter les principes FAIR (cf. section 2), afin que le travail puisse bénéficier à d’autres chercheurs :
- Les ressources sont associées à un identifiant pérenne (DOI), sont décrites par des métadonnées et déposées dans un entrepôt de données (Zenodo) ;
- Des liens explicites sont effectués entre les articles publiés (décrits sur HAL) et les ressources et outils déposés sur Zenodo ;
- Les ressources et outils sont librement téléchargeables12 et réutilisables, suivant une licence Creative Commons CC-BY-SA.
3.2. Contributions au rayonnement des langues du projet
Une autre manière de mesurer l’impact du projet est de vérifier s’il a eu un impact positif sur le rayonnement des langues minoritaires concernées. Deux types de publics sont ici concernés : les chercheurs et les locuteurs des langues.
Du point de vue de la recherche, la mise à disposition des ressources du projet devrait permettre de favoriser les travaux d’autres chercheurs. Ainsi, le corpus annoté pour l’alsacien a été utilisé dans (Millour et al., 2020) et la base textuelle BaTelÒc est utilisée fréquemment par les chercheurs qui travaillent sur l’occitan, par exemple (Esher 2018), (Bach, à paraître) ou sur d’autres langues romanes, comme le catalan (Garcia-Sebastià, 2018, Pujol i Campeny, 2020). Les chercheurs du projet continuent à exploiter les corpus annotés, le corpus occitan a ainsi été utilisé pour poursuivre la chaine de traitement avec l’étape de l’annotation syntaxique (Miletic et al., 2019, 2020).
Un autre aspect important concerne la reconnaissance de ces travaux par la communauté scientifique. Or, le travail sur des langues peu dotées nécessite souvent de construire des ressources et outils à partir de rien ou presque, ce qui peut conduire à un sentiment d’infériorité par rapport aux langues qui disposent de plus de ressources (ressources humaines, ressources financières et état de l’art plus avancé). La production de ressources linguistiques exige du temps et des moyens, et les deux sont rares pour les langues peu dotées. Ces contraintes extrinsèques sont difficiles à contrôler, mais ne doivent pas compromettre la volonté des chercheurs de continuer à travailler sur ces langues. Pour ce faire, les organismes de financement ainsi que les comités de programme et de lecture doivent reconnaître les défis particuliers que pose le travail sur les langues peu dotées. L’inévitable « retard » de ces langues sur les langues mieux dotées conduit trop souvent à une évaluation scientifique négative faisant état d’un manque d’originalité des travaux. Aider les chercheurs à relever ces défis relève selon nous du simple respect d’un principe d’égalité entre les humains et les langues qu’ils parlent, comme le résume la formule de Marcel Félix Castan, emblématique du Forom des Langues du Monde de Toulouse, « les langues et les cultures du monde sont égales entre elles comme les citoyens d’une même république »13.
Certains des travaux développés, en particulier les bases textuelles et les dictionnaires en ligne sont largement utilisés par les apprenants et les locuteurs experts que sont les traducteurs et les enseignants des langues concernées. Nous en avons des preuves avec l’utilisation croissante de l’application Dico d’Òc par les apprenants de l’occitan (enseignement secondaire, universitaires, formation pour adultes) et par l’utilisation croissante également de Batelòc par les enseignants d’occitan et les traducteurs.
Enfin, l’impact sur les locuteurs ordinaires est plus indirect. En effet, la plupart des ressources et outils constitués dans le cadre du projet ne sont pas directement destinés au grand public. Il n’en reste pas moins que les ressources collectées peuvent permettre de développer des outils utiles à tous. Ainsi, les corpus collectés pour l’alsacien et l’occitan ont été utilisés pour deux claviers prédictifs pour smartphones14. Par ailleurs, l’existence de travaux scientifiques sur ces langues conduit à les légitimer et augmenter leur visibilité. Ces travaux suscitent aussi l’attention des médias : le projet RESTAURE a ainsi bénéficié d’une couverture médiatique par différentes chaînes de télévision et stations de radio (France 3 Sud, Alsace 20, France Bleu Elsass, etc.).
Conclusion et perspectives
Nous avons, dans cet article, fait le bilan d’un projet visant à améliorer l’assise numérique de trois langues régionales de France. Sans pour autant évacuer les défis inhérents à un travail collaboratif et interdisciplinaire sur des langues très différentes, nous avons montré qu’il est possible d’aboutir à des résultats concrets grâce à la mise en place de principes simples mais efficaces : collaboration entre chercheurs, réutilisation et recyclage d’outils, utilisation de standards et diffusion des ressources. Nous avons également tiré un certain nombre de leçons de ce projet, qui pourront être utiles aux chercheurs souhaitant se lancer dans une entreprise similaire : importance de la coopération, nécessaire prise en compte du statut particulier des langues peu dotées par rapport au numérique, exploitation de l’existant, efforts axés sur les données plutôt que sur les outils. Pour reprendre à notre compte l’adage bien connu (« A dwarf standing on the shoulders of a giant may see farther than a giant himself », Robert Burton, utilisé par Soria, Mariani et Zoli, 2013 dans le titre de leur l’article), nous pouvons résumer ces diverses leçons de la manière suivante : « Un nain debout sur les épaules d’autres nains peut voir presque aussi loin qu’un géant. »
Nous avons conscience que le chemin à parcourir est encore long pour assurer l’avenir numérique de l’alsacien, de l’occitan et du picard, mais nous espérons avoir pu contribuer à améliorer la situation pour ces langues.