Un problème de culture visuelle
Le 15 mars 2019, un homme armé de plusieurs fusils d’assaut se rend dans deux mosquées de la ville néo-zélandaise de Christchurch et ouvre le feu sur toutes les personnes qu’il croise. L’attentat est filmé par son auteur à l’aide d’une caméra GoPro qui lui permet d’en diffuser les images en direct sur Facebook. La diffusion dure 17 minutes, pendant lesquelles ni les 3000 modérateurs de l’entreprise, ni les intelligences artificielles censées repérer des « contenus inappropriés » ne réagiront1. Ces dernières semblent bien moins sensibles à des images d’attentat qu’à des représentations de tétons, qu’elles reconnaissent et suppriment avant même leur mise en ligne.
On peut s’interroger sur les choix discutables qui conduisent Facebook à censurer certains contenus plutôt que d’autres, et expliquer ces 17 minutes par la tolérance de l’entreprise à l’égard de nombreuses autres formes de représentations de scènes de violence tout à fait communes, comme les fictions cinématographiques. Mais dans le prolongement de cette question, le filtrage des contenus sur ce type de plateforme se présente comme une tâche bien compliquée. En 2018, 243 000 photos ont été ajoutées chaque minute en moyenne. Il y avait au total fin 2018, environ 240 milliards d’images sur Facebook2. Face à un tel volume, les yeux humains ne sont pas assez nombreux ni assez rapides pour faire un travail de discrimination qui a donc été confié à des machines, plus précisément des intelligences artificielles, dont les performances, fruit d’un apprentissage profond (deep learning), sont tant vantées depuis quelques années. Les réseaux de neurones artificiels semblent capables de voir à notre place et de prendre des décisions sur le produit de leurs observations. Or les résistances que nous opposent depuis des siècles, à nous humains, les images et leur interprétation, ne semblent pas tomber si facilement. En quoi la vidéo d’un attentat se distingue-t-elle d’une séquence de jeu vidéo ? Et en quoi le téton qui pointe dans une image pornographique se distingue-t-il de celui d’une vénus allongée dans une peinture de la Renaissance ? Deux images semblables peuvent véhiculer des idéologies fondamentalement différentes. Et il n’y a aucune raison de croire que les machines s’en sortent mieux que les humains face à un problème qui, malgré les milliers de pages que la philosophie ou l’esthétique lui ont consacrées, reste entier pour nous. Pour le dire à cette étape introductive de manière simple, les images convoquent un voir qui est aussi un savoir, et qui nous empêche de décider positivement de leur sens sur une seule base phénoménologique ou perceptive. Le « contenu sémantique », ce Graal des réseaux sociaux, semble bien résister au regard machinique, pour lequel une image n’est, après tout, qu’une suite de chiffres. C’est pourtant cette question qui a constitué le moteur des recherches en intelligence artificielle dans le domaine visuel. Comment le sens vient-il à l’image ? Ou comment passer de l’image au sens, alors qu’une caméra numérique ne peut « voir » que des pixels – c’est-à-dire des chiffres ?
Avant de faire quelques remarques méthodologiques sur cette question, j’aimerais préciser ici qu’elle se formule simultanément de manière inverse : comment passer du sens à l’image ? Car il ne s’agit pas seulement pour les machines de « voir », mais aussi de concevoir, de produire du visuel. Il faut se rendre à l’évidence : depuis maintenant quelques années, notre environnement est occupé par des images totalement nouvelles, non pas dans leurs apparences ou leurs sujets – ces images sont on ne peut plus banales : chats, voitures, maisons – mais dans leur mode de production. Ces images sont inédites car elles ne sont pas produites par des humains mais par des réseaux profonds de neurones. Mis en ligne récemment, le site ThisPersonDoesnotExist présente à chaque chargement de la page d’accueil une image d’une personne qui « n’existe pas », entièrement construite de toutes pièces par une intelligence artificielle. De la même manière, d’autres réseaux de neurones peuvent dorénavant produire des représentations plutôt crédibles de façades de maison, d’animaux ou d’objets divers à partir de quelques indications de départ. Mais à partir de quoi ces représentations sont-elles construites ? Comment une machine peut-elle connaître une catégorie d’objets au point d’être capable d’en produire une image ?
Apprendre à voir et à dessiner à une machine nous impose de redéfinir ce que le « voir », comme processus nécessairement imprégné par un savoir, peut bien vouloir dire. Si ce problème peut sembler ne se poser que depuis ses disciplines afférentes – les mathématiques, l’informatique ou les sciences cognitives – il s’avance avec insistance sur les terrains éthique et sociologique, car l’usage de la vision artificielle s’étend, au-delà de mes exemples introductifs, à des activités de plus en plus nombreuses et diversifiées, comme la conduite automatique, le diagnostic médical, les procédés de contrôle industriels, la surveillance. En portant sur les processus d’apprentissage et notre façon de construire le monde par le regard, ce problème relève par ailleurs de la psychologie de la perception, lorsqu’elle dialogue avec l’esthétique et la philosophie. Irréductible à un champ du savoir spécifique, le problème de la vision des machines est fondamentalement un problème de culture visuelle. Et c’est à ce titre qu’il nous concerne. Or comme le dit très bien l’artiste et géographe Trevor Paglen, ce que ce problème est en train de transformer, c’est la culture visuelle elle-même, lorsqu’elle se détache des yeux humains, pour aller s’adresser prioritairement à des machines3 À l’image du cerveau, les réseaux de neurones sont souvent mobilisés comme des boîtes noires sur lesquelles nous projetons toutes sortes d’inquiétudes ou d’espérances et qui semblent résister à la moindre tentative de description. Pour tenter de comprendre ce que « voir » peut bien vouloir dire pour une machine, je vais interroger dans ce texte la manière dont les réseaux profonds de neurones apprennent à lier ensemble le langage, le monde et la pensée.
Du détail à la vue d’ensemble : la construction du regard machinique
C’est bien la trace d’une facture, d’une couture ou d’une brisure (dans la texture des pixels) que le regard cherche invariablement dans le détail des portraits de ces « personnes qui n’existent pas4 », comme dans ces images d’objets ou d’animaux.
Portraits et détails générés par des réseaux antagonistes génératifs
https://thispersondoesnotexist.com/. Goodfellow, Ian J., Jean Pougeat-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, et Yoshua Bengio. 2014. « Generative Adversarial Networks ». arXiv:1406.2661 [cs, stat], juin.
http://arxiv.org/abs/1406.2661
La nature de ces images impossibles semble résider dans des « traces » : une oreille mal placée dans un visage, une dent curieusement orientée dans la gueule d’un chat, une fenêtre étrangement raccordée à un toit dans une architecture… ces détails dissonants s’offrent comme autant de raisons de douter de ce que nous voyons, de chercher à distinguer le vrai du faux.
Série de représentations de chats produites par des réseaux antagonistes génératifs
Karras, Tero, Samuli Laine, et Timo Aila. 2018. « A Style-Based Generator Architecture for Generative Adversarial Networks ». arXiv:1812.04948 [cs, stat], décembre.
http://arxiv.org/abs/1812.04948
Ces images sont toutes réalisées à l’aide de réseaux antagonistes génératifs (GAN5), constitués en fait de deux réseaux de neurones profonds confrontés l’un à l’autre. Le premier (génératif) est entraîné à produire des images les plus réalistes possibles, qui sont alors soumises au second (discriminatif), dont l’unique tâche est de discerner ce qui lui semble vrai de ce qui lui semble faux6. Les auteurs l’expliquent de cette manière : « Le modèle génératif peut être considéré comme une équipe de faussaires qui tentent de produire de la fausse monnaie et de l’utiliser sans se faire repérer, tandis que le modèle discriminatif est un peu comme la police qui cherche à détecter la contrefaçon. La concurrence dans ce jeu pousse les deux équipes à améliorer leurs méthodes jusqu’à ce que les contrefaçons soient indiscernables des originaux7 ».
Puisqu’il est ici question d’image, cette compétition doit plutôt nous évoquer le jeu auquel se livrent le faussaire de tableaux8 et l’amateur d’art au regard aiguisé, sensibilisé à ces « traces » dont l’usage avait si bien été décrit, au croisement de l’histoire de l’art, de la psychanalyse et de l’enquête criminelle, par Carlo Ginsburg9. Si c’est par le détail que notre regard entre dans ces portraits, c’est aussi par là que les réseaux de neurones artificiels ont appris à les réaliser. Pour s’en rendre compte, il n’est pas inutile de remonter à la naissance de l’intelligence artificielle. Celle-ci est couramment située en 1956, au moment de la conférence du Dartmouth College, université privée nord-américaine qui réunit alors à peu près tous les scientifiques qui feront, dans les vingt années suivantes, des avancées significatives en la matière. Dans cette association de termes inventée par John McCarthy et Marvin Minsky, l’intelligence est entendue comme une capacité à « manipuler les symboles », déjà préfigurée par Leibniz 250 ans plus tôt10, et entérinée par les sciences cognitives alors en plein développement. Il s’agit de doter les machines d’un raisonnement autonome qui réside essentiellement dans une capacité à calculer des symboles selon des règles programmées.
Cette idée pose le cadre des ambitions de la branche historique de l’intelligence artificielle, dite symbolique11 ou cognitive12, associée aux noms d’Alan Newell et Herbert Simon, qui avaient développé en 1955 le premier programme destiné à modéliser le fonctionnement de l’esprit à l’aide du traitement symbolique13. Or les « intelligences artificielles » qui connaissent à partir des années 2000 de spectaculaires avancées dans le domaine de la vision sont le produit d’une conception radicalement différente de ce cadre inaugural. L’apprentissage profond qui caractérise ces modèles récents va plutôt chercher ses sources dans la cybernétique et le behaviorisme, qui évacuent de la machine le problème du raisonnement au profit de son comportement. Les réseaux profonds de neurones ne suivent pas des règles logiques préétablies pour en déduire des cas particuliers ; ils sont plutôt conçus pour découvrir d’eux-mêmes des représentations appropriées, en optimisant leur marge d’erreur au cours d’un processus d’apprentissage. Les systèmes que nous croiserons plus loin sont tous conçus sur ce même modèle, dit « connexioniste », car il fait reposer les représentations qu’il construit sur la nature même des connexions entre les éléments dont il est composé. Étroitement associée à la reconnaissance visuelle, son histoire est marquée par les travaux fondateurs de Frank Rosenblatt au laboratoire d’aéronautique de l’Université Cornell à partir de 1957. Rosenblatt conçoit ce qu’il appelle le « perceptron14 », un système qui met en réseau des neurones formels, dont le fonctionnement avait été modélisé dès les années 1940 par Warren McCulloch et Walter Pitts15.
Diagramme du Mark 1 Perceptron
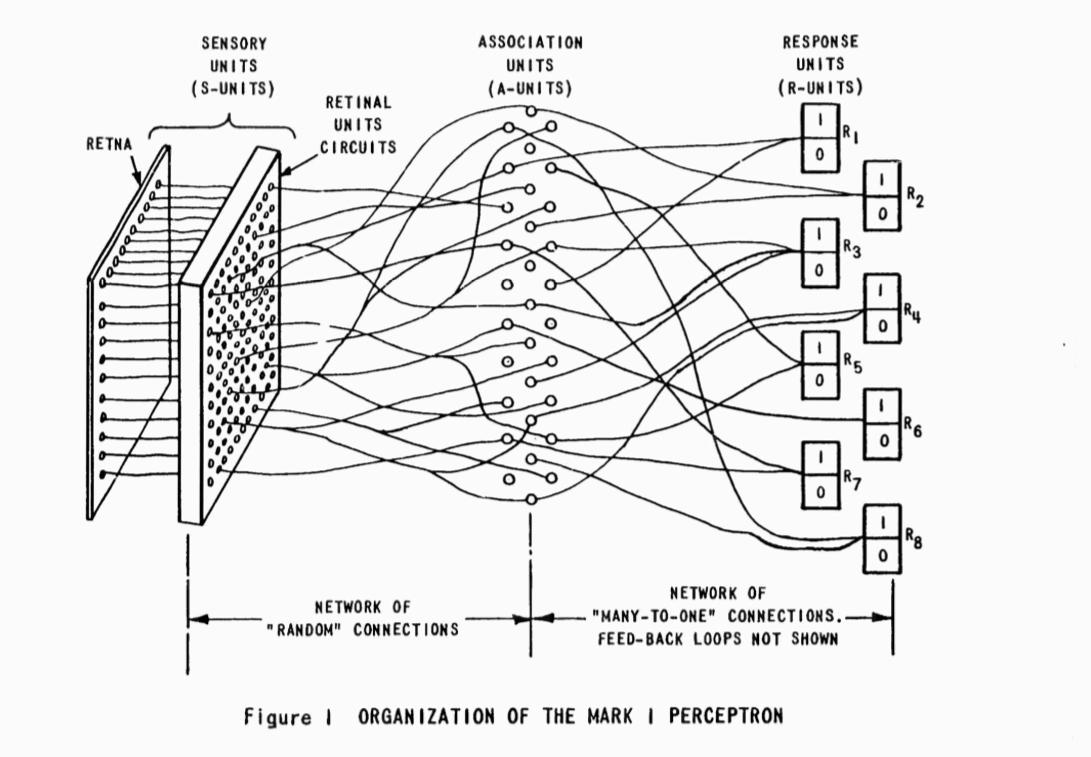
Mark I Perceptron Operators’ Manual. Buffalo, NY: Cornell Aeronautical Laboratory, 1960.
Frank Rosenblatt et Charles Wightman, 1957
Un neurone de ce type est tout simplement un opérateur qui fait une somme pondérée de ses entrées, c’est-à-dire une somme des informations qu’il reçoit – chacune de ces informations étant minimisée ou maximisée selon l’importance relative (le poids) de l’entrée à laquelle elle se présente16. La nouveauté du Perceptron consiste à introduire un principe de feedback dans ce modèle, afin de modifier progressivement les poids des entrées au cours d’une phase initiale d’apprentissage17. Le perceptron pouvait donc être entraîné à « reconnaître » des échantillons visuels en incorporant sa marge d’erreur pour améliorer ses réponses, et peut à ce titre être considéré comme la première machine apprenante. Il faut cependant nuancer la performance de ce système, qui, selon Rosenblatt, « peut faire la différence entre un chat et un chien, bien qu’il ne serait pas capable de dire si le chien est à la gauche ou à la droite du chat. Pour le moment, il n’a pas d’utilité pratique […] mais un jour, il pourrait être utile d’en envoyer un dans l’espace pour voir à notre place (to take in impressions for us18). Rosenblatt ne se doutait pas que les principes de l’apprentissage profond en plein essor de nos jours seraient directement empruntés à ce réseau primitif. Après avoir fait l’objet de recherches intenses dans les années 1960, les réseaux de neurones artificiels seront cependant relativement délaissés dans la décennie suivante19, au profit d’approches symboliques, qui, dans le domaine de la vision, vont plutôt chercher à « instruire la machine » pour lui permettre d’appréhender des univers clos et simplifiés. C’est du moins, au début des années 1970, la démarche de Marvin Minsky, qui développe avec le mathématicien Seymour Papert des « micromondes20 » de blocs au MIT, dont les structures pouvaient être appréhendées par un ordinateur muni d’une caméra.
Le problème de la vision reçoit ici une réponse bien différente du comportement adaptatif du Perceptron. Il s’agit de modéliser le raisonnement au cœur de la machine, en s’appuyant sur les avancées des sciences cognitives. Il faut rappeler que Papert avait collaboré avec Jean Piaget entre 1958 et 1963 au sein du Centre international d’épistémologie génétique de Genève. Papert s’intéresse alors de près à l’apprentissage fondé sur l’expérience, qu’il aborde dans un texte de 1963 en décrivant les principes par lesquels il serait possible d’en reproduire les structures sur ordinateur21. L’expérience des micromondes a indéniablement bénéficié de l’apport des notions piagéennes de régulation, d’assimilation22, mais surtout de schème, une notion qui peut trouver son équivalent dans les « cadres » (frames), théorisées par Minsky en 197523.
L’approche cognitiviste va ainsi tenter de donner ces cadres à la machine, là où le connexionisme, héritier du perceptron, va plutôt faire en sorte qu’ils soient construits par la machine à partir des exemples d’apprentissage. On peut reprendre ici la distinction faite par Dominique Cardon et al. entre ces deux démarches opposées : la première, hypothético-déductive, offre une place centrale au programme, qui permet à la machine d’appréhender par déduction des cas particuliers ; la seconde, inductive, laisse le soin à la machine de trouver son programme elle-même, pour l’appliquer ensuite à des situations nouvelles24. Mais si les expériences de Minsky et Papert au MIT sont ambitieuses, elles déçoivent cependant les attentes et ne trouvèrent pas de prolongements marquants dans le domaine de la reconnaissance visuelle, qui va plutôt devenir le terrain de jeu des réseaux de neurones. Les approches connexionistes vont ainsi ressurgir au cours des années 1980 et 1990, défendues notamment dans un ouvrage marquant publié en 1986 en deux volumes par le groupe de recherche PDP25. Les ordinateurs ont alors gagné en puissance, et les réseaux peuvent additionner des couches de neurones pour s’organiser en structures bien plus complexes.
Diagramme d’un réseau de neurones artificiels avec deux couches intermédiaires
Le chercheur en intelligence artificielle Yann Lecun travaille à partir de 1988 sur la reconnaissance des images par ces techniques de manière indirecte : en mettant au point, au sein du laboratoire d’AT&T, une technique d’apprentissage et de reconnaissance de caractères26. Le véritable apport de cette technique réside dans un algorithme qui permet, au cours d’un apprentissage supervisé, de renvoyer au travers du réseau la marge d’erreur mesurée en sortie, pour modifier les poids synaptiques de chaque entrée de neurone et progressivement converger vers la réponse attendue. Si cet algorithme dit de « rétropropagation de gradient stochastique » est le fruit de plusieurs recherches dont les plus anciennes remontent aux années 1970, son efficacité sur les images est véritablement démontrée au milieu des années 198027. C’est aussi l’augmentation de la taille des bases de données d’images étiquetées qui a véritablement permis de faire ses preuves à cette approche, qui consomme un grand nombre d’exemples au cours de la phase d’apprentissage. Apprendre à un réseau de neurones à « reconnaître » un chat consiste à lui présenter des milliers d’images différentes de chats (photographiques, dessinées, de différentes tailles, formes, races, dans différentes postures et selon différents cadrages28. Progressivement, un tel réseau modifie les filtres par lesquels il perçoit ce qui lui est présenté, pour se faire une « idée » de ce qu’est un chat, découvrant par lui-même ce que mille images de chats ont en commun29.
Dans cette curieuse opération prédictive, c’est la force des connexions du réseau qui se transforme d’elle-même de manière statistique. À l’inverse des modèles symboliques des premières heures de l’intelligence artificielle, les réseaux de neurones fonctionnent de manière non séquentielle, non centralisée, non hiérarchisée30. Ils remontent des cas particuliers vers une représentation générale qui n’est pas donnée à l’avance ni stockée dans un programme à un endroit bien identifié du réseau. On peut aussi se représenter l’activité de ce genre de réseaux comme une recherche d’invariants dans un ensemble incroyablement diversifié. Sur un plan purement descriptif, apprendre à voir à une machine reviendrait ainsi à modéliser les « paramètres explicatifs » des objets du monde, et rejoindrait le vieux rêve positiviste d’une mise en données ou d’une mathématisation du monde31. Mais en quoi consistent ces paramètres explicatifs ? Qu’est-ce que ces réseaux parviennent à modéliser ? Quelles représentations se font-ils des objets qu’ils semblent arriver, au terme d’un apprentissage, à « connaître » ? Ces questions semblent bien s’imposer comme préalable dès lors que nous voulons confier à des machines le soin de voir à notre place.
Rêves profonds
En 2012, un algorithme réussit, lors du concours « Large Scale Visual Recognition Challenge », à faire descendre sa marge d’erreur à 16%, bien en dessous de tout ce qui avait été réalisé lors des années précédentes. Le réseau qui obtient cette performance a été conçu par Alex Krizhevsky, Ilya Sutskever, et Geoffrey E. Hinton de l’Université de Toronto32. Il a la particularité d’être profond et d’être construit de manière convolutive33. Le principe de la convolution consiste à analyser des images à l’aide de filtres plus petits, sensibles à un motif spécifique (arrêtes, contours orientés), et conçus pour activer ou inhiber des neurones artificiels de la couche suivante selon que ce motif est détecté ou non. Cette nouvelle couche est ensuite analysée de la même manière par d’autres filtres, sensibles à d’autres motifs un peu moins élémentaires (formes primaires, motifs) et ainsi de suite, de couche en couche.
Diagramme de l’architecture d’un réseau à convolution
Cet exemple est celui de LeNet-5, conçu par l’équipe de Yann LeCun en 1998 pour la reconnaissance de caractères. LeCun, Yann, L.Bottou, Yoshua Bengio, et P. Haffner. 1998. « Gradient-Based Learning Applied to Document Recognition ». Proceedings of the IEEE 86 (11): 2278-2324
La profondeur du réseau permet de progresser par niveaux croissants de complexité, depuis les premières couches sensibles à d’infimes détails, jusqu’aux dernières, dédiées à des formes complexes et composées34.
Représentation des motifs auxquels sont sensibles les différents filtres d’un réseau à convolution
Du plus simple dans les couches basses, au plus complexe dans les couches supérieures. Zeiler, Matthew D., et Rob Fergus. 2013. « Visualizing and Understanding Convolutional Networks ». arXiv:1311.2901 [cs], novembre.
http://arxiv.org/abs/1311.2901
Exemple de reconnaissance d’image par des légendes, réalisé à l’aide du réseau à convolutions DenseCap
Johnson, Justin, Andrej Karpathy et Li Fei-Fei. 2015. « DenseCap: Fully Convolutional Localization Networks for Dense Captioning ». arXiv:1511.07571 [cs], novembre.
http://arxiv.org/abs/1511.07571
Cette progression hiérarchique permet au réseau de se construire une idée du monde à partir de ses détails. Le monde visuel serait « compositionnel », comme le terme de Le Cun35, c’est-à-dire qu’il peut être envisagé comme un assemblage d’éléments de complexité croissante. Les travaux des neurobiologistes David Hunter Hubel et Torsten Nils Wiesel sur le cortex visuel des chats dans les années 1960, souvent mobilisés dans la recherche en intelligence artificielle, avaient d’ailleurs mis en évidence le même principe de composition progressive des formes à partir de bribes élémentaires au sein des aires visuelles36. Appréhender le monde à partir du détail permettrait à ces réseaux de produire de la généralité, c’est-à-dire, de se construire, par abstraction progressive, des représentations qui tiennent dans l’apprentissage un rôle semblable à celui que Piaget faisait tenir aux schèmes. Les schèmes sont des structures qui se construisent au fur et à mesure de la répétition d’une action, et qui permettent ensuite d’appréhender des situations nouvelles37.
Si les recherches de Piaget n’ont jamais directement porté sur l’intelligence artificielle, elles ont trouvé de nombreux échos en la matière. Ainsi le schème s’apparente au « cadre » (frame) de Minsky que j’évoquais plus haut38. De l’aveu de l’auteur, l’idée de cadre n’est pas une nouveauté, mais trouve son équivalent dans les schémas du psychologue F.C. Bartlett, ou encore les paradigmes chers à Thomas Kuhn39 Si le schème, le cadre, le paradigme, peuvent s’apparenter à des représentations mentales, nous pourrions même en faire remonter les sources à Kant. Mais dans le contexte de la vision, ces notions ont une histoire qui mérite par ailleurs d’être éclairée par les réflexions d’Ernst Gombrich. Dans ses travaux sur la représentation picturale, Gombrich insistait sur la fonction directrice des schémas structurant l’expérience. Pour concevoir une représentation, l’artiste ne part jamais de rien. Ce que j’ai appelé ici schéma ou cadre, est pour Gombrich un « formulaire de base », que l’on peut, d’une certaine manière considérer comme un ensemble de préconceptions au filtre desquels passe la perception40.
Représenter, pour l’artiste, c’est compléter un « formulaire » existant. « Ce qui est connu et familier restera toujours le point de départ de la représentation de l’inhabituel41 ». Cette idée est très proche de ce que Thomas Kuhn écrivait à quelques années d’écart : « […] quelque chose qui ressemble à un paradigme est indispensable à la perception elle-même. Ce que voit un sujet dépend à la fois de ce qu’il regarde et de ce que son expérience antérieure, visuelle et conceptuelle, lui a appris à voir42 ». Il n’est pas surprenant de constater que les recherches sur la vision artificielle aient eu à faire intervenir ces mêmes concepts pour modéliser la perception. Voir le monde et donner du sens aux choses, c’est faire entrer ce qu’appréhende le regard dans un ensemble de schémas familiers, dont la structure est elle-même le produit de l’expérience de l’observateur – humain ou non humain. Or nous avons vu que si de tels schémas étaient délibérément insérés dans les machines symboliques, ils ne trouvent aucun équivalent clair dans les réseaux de neurones, dont l’organisation homogène ne permet de produire que des représentations non symboliques43. C’est d’ailleurs l’une des plus vives critiques qui leur est adressée : ces représentations ne sont après tout « que » le produit mathématique de régularités statistiques44. Ces observateurs non-humains que sont les réseaux peuvent cependant donner l’impression qu’ils possèdent une véritable expérience visuelle. C’est du moins ce qu’a tenté de faire apparaître le programme DeepDream45, conçu en 2014 par Alexander Mordvintsev. DeepDream est construit de manière à parcourir le type de réseau que je viens de décrire dans le sens inverse. Alors qu’une image de bruit aléatoire est présentée en entrée, des instructions sont données à un neurone de sortie consacré au classement d’un type particulier d’image, afin qu’il obtienne un score plus élevé que les autres – et qu’il force le réseau, par conséquent, à produire ce type d’image.
Les premiers exemples d’images obtenues à partir d’un bruit blanc présenté en entrée d’un réseau, par Alexander Mordvintsev et son équipe

Mordvintsev, Alexander, Christopher Olah et Mike Tyka. 2015. « Inceptionism: Going Deeper into Neural Networks ». Google AI Blog (blog). 17 juillet 2015.
http://ai.googleblog.com/2015/06/inceptionism-going-deeper-into-neural.html.
Le réseau va alors modifier l’image de départ pour la faire tendre vers cette catégorie, en faisant apparaître les objets afférents. Les premiers exemples pris par les auteurs nous montrent des images de bananes, de fourmis, de vis, reconstruites ex-nihilo par le réseau. Mais les trois ingénieurs ont aussi essayé de partir d’une image existante en demandant à l’une des couches du réseau d’accentuer les détails auxquels elle est sensible. Largement diffusées ces dernières années, les images ainsi produites donnent à voir des paysages improbables composés d’objets, de visages ou de têtes d’animaux, que le programme fait littéralement apparaître dans les visuels qu’on lui soumet : un plat de spaghettis, une voiture, un portrait de groupe, une reproduction de la Joconde, un ciel nuageux… se compliquent alors de formes ou d’animaux impossibles, saturés de couleurs et parsemés d’yeux, de pattes ou de museaux. Aussi surprenants soient-ils, ces détails doivent cependant rappeler quelque chose à quiconque a déjà observé des nuages en laissant aller son imagination. L’opération qui consiste à déceler au sein des nuées, des visages ou des animaux, ou essayer d’y découvrir un motif signifiant est communément appelée paréidolie, du grec para, « à côté de » et eidôlon, « image, apparence ». Si la paréidolie peut naître de tout type de choses, le nuage semble particulièrement approprié pour cet exercice de perception.
Images de ciel avant et après traitement par DeepDream

Alexander Mordvintsev et son équipe, 2015. Mordvintsev, Alexander, Christopher Olah et Mike Tyka. 2015. « Inceptionism: Going Deeper into Neural Networks ». Google AI Blog (blog). 17 juillet 2015.
http://ai.googleblog.com/2015/06/inceptionism-going-deeper-into-neural.html.
Les détails apparaissant dans l’image précédente

Alexander Mordvintsev et son équipe, 2015. Mordvintsev, Alexander, Christopher Olah et Mike Tyka. 2015. « Inceptionism: Going Deeper into Neural Networks ». Google AI Blog (blog). 17 juillet 2015.
http://ai.googleblog.com/2015/06/inceptionism-going-deeper-into-neural.html.
Car un nuage a rarement la forme d’un nuage. Il a la forme de ce que nous avons en tête lorsque nous l’observons. Mais qu’est-ce que les réseaux convolutifs ont-ils en tête ? En se laissant aller à cet exercice de « projection dirigée46 », les réseaux de neurones empruntent une voie déjà décrite par Léonard de Vinci47, mais aussi par Hermann Rorschach48, pour nous donner à voir les schémas qui font sens à leurs yeux artificiels.
Image générée par DeepDream à partir d’un bruit blanc
Leonid Berov, 2016. Berov, Leonid. 2016. « Visual Hallucination For Computational Creation »
Ici encore, la modélisation connexioniste engendre sans surprise des phénomènes largement décrits par la psychologie, qu’il faut cependant rapporter au processus d’apprentissage dont ils sont le produit. À partir de quoi ces réseaux ont-ils appris ce qu’ils connaissent ?
Pourquoi regarder les machines ?
Comme je l’écrivais plus haut, un certain nombre d’analogies entre l’homme et la machine ont inspiré les recherches sur l’apprentissage visuel par les intelligences artificielles. L’une d’entre elles a consisté à poser que pour connaître le monde, il faut en faire l’expérience. Apprendre à voir est étroitement lié au fait d’apprendre à nommer ce que l’on voit. Dans le cas des machines, c’est aussi par le langage que passe l’apprentissage du regard, qui consiste dès lors à pouvoir classifier, donc à nommer des objets. L’apprentissage supervisé vise à établir et à renforcer une capacité à généraliser, une capacité à pouvoir reconnaître l’image d’un type d’objet après avoir vu un grand nombre de représentations de ses occurrences. La première asymétrie entre l’homme et la machine apparaît d’emblée ici : alors que les images n’entrent que partiellement en jeu dans l’apprentissage humain, elles constituent la principale source employée à ce jour pour les machines. Loin d’être anecdotique, cette différence doit attirer notre attention sur le fait que les intelligences artificielles construisent une connaissance non pas du monde lui-même, mais du monde des images, qui a ses distorsions, ses limitations, et ses biais. Le plus large corpus d’images annotées destinées à l’entrainement à ce jour est la base ImageNet, constituée à partir de 2009 par des chercheurs des départements de science informatique des Universités de Princeton et Stanford sous la direction de Fei Fei Li, professeur d’informatique à Stanford et co-directrice des instituts d’intelligence artificielle ainsi que de vision et d’apprentissage de Stanford49.
Avec près de 15 millions d’images réparties en plus de 20 000 catégories50, ImageNet, nous dit-on, « vise à fournir la couverture la plus complète et la plus diversifiée du monde de l’image51 ». On peut cependant s’interroger sur la moyenne visuelle que produit le protocole suivi par l’équipe de Fei Fei Li, qui, sur le fond, exclut a priori les images gênantes, ambigües, offensantes, et sur la forme, se limite à des choses « dicibles », c’est-à-dire susceptibles de faire l’objet, non seulement d’une description textuelle, mais également d’un consensus sur cette description52. Car pour annoter manuellement cet ensemble monstrueux d’images, l’équipe s’est tournée vers le crowdsourcing, en déléguant ce travail à des milliers de personnes à travers le monde grâce à la plateforme Amazon Mechanical Turk53. Et pour organiser les images entre elles, Li a décalqué la structure modélisée dans la célèbre base lexicale Wordnet54, en partant du principe que l’organisation sémantique du langage est « très proche » de la vision humaine, car, selon elle, « les mots (labels) du langage reflètent le monde visuel55 »
L’entrée « Catbox » sur le site ImageNet
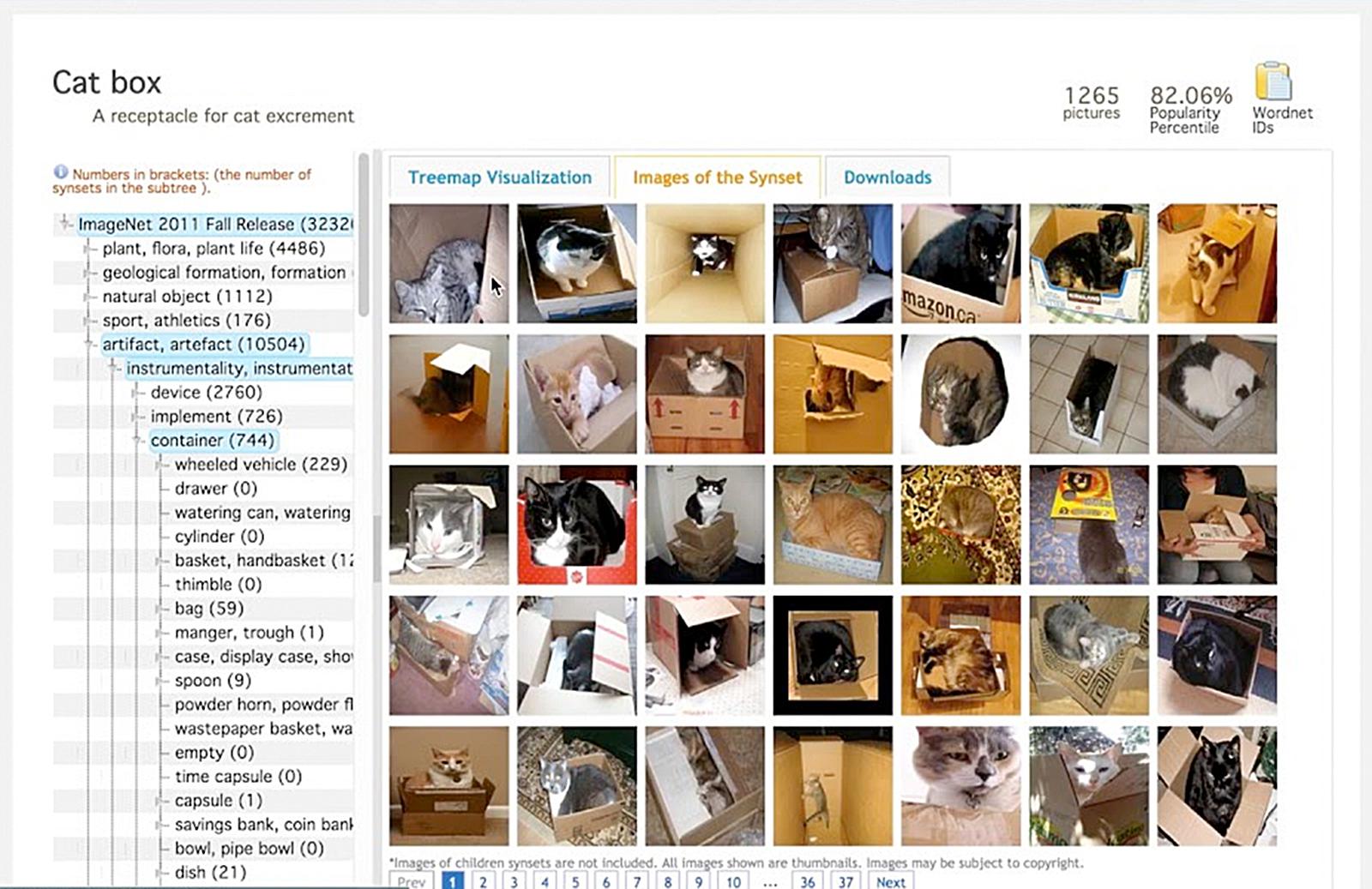
http://www.image-net.org/
Deux branches de la structure d’ImageNet
Deng, Jia, Wei Dong, Richard Socher, Lia-Jia Li, Kai Li et Li Fei-Fei. 2009. « ImageNet: A large-scale hierarchical image database ». In 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248-55. Miami, FL: IEEE.
Les intelligences artificielles ne sont peut-être qu’une nouvelle manière de poser de vieux problèmes, bien souvent posés dès l’antiquité56. Une telle remarque montre à quel point la vision reste tributaire, au cours de l’apprentissage, d’une structure linguistique. Et si au mieux, nous pourrions interpréter la proposition de Li à la lumière des tentatives positivistes pour faire correspondre la réalité sensible à l’espace logique du langage57, nous savons à quel point ces tentatives de mise en ordre sont partielles et contingentes.
« L’ordre, c’est à la fois ce qui se donne dans les choses comme leur loi intérieure, le réseau secret selon lequel elles se regardent en quelque sorte les unes les autres et ce qui n’existe qu’à travers la grille d’un regard, d’une attention, d’un langage58 ». Cette remarque de Michel Foucault souligne les glissements qui s’opèrent entre le langage et le monde, dans un rapport qui, jamais fixé de manière définitive, doit forcément résister aux mises en chiffres et en fonctions mathématiques. Les cadres de l’expérience que construisent les intelligences artificielles pour voir le monde sont donc tributaires de la manière dont les bases d’images d’apprentissage comme ImageNet lient ensemble les mots et les choses. Et au-delà d’ImageNet, ce sont l’ensemble des réseaux sociaux qui servent à présent de bases d’apprentissage. Après tout, les images y sont annotées par leurs auteurs. Or en aspirant le contenu visuel d’internet, ces bases en reproduisent les lacunes et les excès, et bien sûr les obsessions. On ne s’étonnera pas de trouver autant d’images d’animaux dans l’histoire récente de la vision artificielle : le monde numérique en est peuplé. En témoignent les exemples qui ponctuent mon texte depuis le début. Il est à ce titre probable que les plus fines connaissances en matière de représentation de chatons soient de nos jours détenues par un algorithme. Et nous pourrons certainement dire rétrospectivement que les chats et les chiens, et plus généralement, les animaux, auront joué un rôle non négligeable dans la construction de la relation homme-machine59. Abreuvés d’innombrables images humaines d’animaux, les réseaux de neurones rejouent d’ailleurs, dans leurs réussites et dans leurs échecs, quelque chose du regard animal. Ainsi, les zèbres par exemple semblent poser aux machines les mêmes problèmes de reconnaissance qu’à leurs prédateurs, leurrés par des motifs naturellement prévus pour le camouflage et la dissimulation. En retour, ce sont des stratégies semblables qui sont imaginées par les humains eux-mêmes pour ne pas se faire reconnaître sur les réseaux sociaux qu’ils fréquentent60. Le regard machinique consiste ici à « prendre » et à éviter « d’être pris », selon ce jeu du chat et de la souris auquel s’adonnaient les réseaux antagonistes du début de mon texte. Un tel jeu nous renvoie à ce rapport paradoxal de la vérité et de l’illusion que WJT Mitchell a très bien décrit à partir de l’altérité du regard animal61. Bien-sûr, Mitchell historicise l’asymétrie entre les regards humain et animal pour interroger la fonction politique et sociale de l’illusion esthétique. Or si pour ce faire, l’auteur préconise, dans le prolongement de John Berger62, d’apprendre à nouveau à regarder les animaux, nous pourrions ajouter qu’il faut aussi regarder les machines.
Formes de vie
Les modèles de réseaux présentés au fil de mon récit semblent nous entraîner dans un trajet circulaire qui peut être décrit en ces termes : la machine apprend à voir de manière inductive, en se construisant une représentation non symbolique d’un objet après avoir dégagé ce qu’un grand nombre d’images de cet objet ont en commun, pour être ensuite capable de reconnaître mais aussi de générer un nouvel objet dans cette série. La critique symboliste des réseaux connexionistes vise le sens de ces représentations, très éloignées des représentations mentales que le philosophe Jerry Fodor avait mises au cœur des processus cognitifs63. L’esprit était envisagé par Fodor selon le modèle computationnel du langage de la pensée, qui mobilise des symboles dans des opérations logico-mathématiques. Or l’apprentissage profond, difficilement compatible avec ce type de description, s’accorde plus facilement avec des modèles qui rejettent le mentalisme, ou du moins, qui s’en tiennent à une description pragmatique des phénomènes.
Contre le modèle computationnel, le comportement des réseaux profonds face aux images nous invite alors à renouer avec la seconde philosophie de Wittgenstein, qui rapportait l’ensemble des opérations cognitives à l’horizon de nos pratiques quotidiennes et du langage, en refusant d’en donner des explications faisant intervenir des représentations mentales. La description des réseaux profonds par ce paradigme non mentaliste nous permet dès lors de comprendre les limites que leur impose le mouvement circulaire que je viens d’esquisser ici : s’il n’y a rien en dehors de la pratique, s’il n’y a pas d’opération obscure qui préside à l’élaboration des cadres de l’expérience, alors nous comprenons qu’un réseau, aussi profond soit-il, ne peut découvrir que ce qu’il a appris. Les réseaux apprennent à voir selon ce que Wittgenstein appelle un « enseignement ostensif » qui consiste à fixer des relations d’association entre les mots et les choses, en suivant l’idée que « les mots du langage dénomment des objets – les phrases sont des combinaisons de telles dénominations64 ». Wittgenstein ne rejette pas cette conception, mais il insiste sur le fait qu’elle ne recouvre qu’un des aspects du fonctionnement du langage. Car ainsi décrite, elle ne saurait partir « de rien », mais présuppose au contraire déjà le langage65. Comme le démontre Wittgenstein dans l’ensemble des Recherches, il n’y a là qu’une forme « primitive » de la façon dont le langage fonctionne, limitée à un jeu de langage particulier. Or ce que requiert plutôt notre langage de tous les jours, c’est ce que Wittgenstein appelle une « forme de vie66 », c’est-à-dire un arrière-plan communément partagé, qui est précisément constitué de tout ce que l’auteur avait délaissé dans sa première philosophie67 : les valeurs, les émotions, la culture. C’est cet arrière-plan qui donne du sens à ce que nous disons, et non un mode d’emploi des mots que nous aurions entièrement assimilés avant de nous mettre à parler.
Entre le Tractatus et les Recherches philosophiques, publiées 30 ans plus tard, Wittgenstein est passé d’une conception du langage comme image du monde à une conception fondée dans la pratique, les habitudes et la culture. Ce que nous enseignent les Recherches, c’est que le sens que nous donnons aux images – par l’intermédiaire du langage et de la pensée – est profondément tributaire de nos formes de vie, c’est-à-dire d’expériences qui se construisent dans une longue durée en associant étroitement voir et savoir. Si l’apprentissage ne semble pas encore permettre aux réseaux de neurones de distinguer une vidéo d’attentat d’une séquence de jeu vidéo, c’est que les cadres qu’ils construisent ne saisissent le monde que dans ses apparences phénoménales, tel qu’il se donne en x et en y, en dehors du z de la pratique. Et c’est certainement pour dépasser cette limite que se développe l’informatique ubiquitaire68, prophétisée par Mark Wieser au début des années 1990 : pour atteindre qualitativement le regard humain, la machine doit tenter de disparaître pour se fondre au cœur même de nos formes de vie. Si les « images invisibles69 », ou les « photographies sans hommes70 » suivent ce chemin, il faudra que nous conservions notre sens critique en maintenant ouvertes ces boites noires que sont les réseaux de neurones artificiels lorsqu’ils sont systématiquement insérés dans les différents aspects de nos existences.